
The honest answer to why does anyone need an asset management system at home is that I play bass, I produce music, and at some point in the last few years the gear got away from me. Not in a hoarding way. In a working-musician way. Pedalboards rebuilt for one project and stripped for the next. Pedals lent to other bands and never returned because nobody can remember whose Boss DD-8 it actually was. Plugin licences for Logic Pro and Pro Tools spread across vendors I can no longer recite from memory. The studio in Portslade has a bookshelf of hardware that has, over the years, been quietly modded enough that what's in this box is no longer obvious from looking at the box.
I needed a database. I installed Snipe-IT, the open-source asset tracker, and pointed it at the music gear.
That solved one problem and created a more interesting one.
Why an MCP server, and not just the API
Snipe-IT has a proper REST API. It is not the problem. The problem is what happens when you sit at a terminal with Claude open and ask, casually, "what plugins do I own that would suit a slow trip-hop track, and which of those have presets I've already saved?"
What that question actually requires, under the hood, is: list licences in the Plugins category, cross-reference each with its vendor, check which ones I've tagged with my own metadata, then chain through to the asset records for any hardware that pairs with them. That's four or five API calls in sequence, each shape of response slightly different, each one needing to be reasoned about before the next call can be made. The Snipe-IT API can do all of it. It just can't do it fluidly. It's modular by design, which is correct for a REST API and inconvenient for an AI trying to think across entities.

Model Context Protocol, the open standard from Anthropic, is the layer that fixes this. An MCP server exposes tools to a language model in a shape the model can reason about and chain. Less here is a list of HTTP endpoints, good luck. More here is a tool called get_assets_for_licence, here is one called find_licences_by_category, please combine them as needed. The model gets to think in terms of the domain, not the wire format.
So I built one.
Sunday turns into November
I started with the obvious tools. List assets. Check one out. Check one back in. Smoke-tested it against my own studio inventory, asked Claude what bass I had checked out to which musician, got the right answer back, felt the small specific thrill of a thing that worked.
Then I kept going.
This is also how I learned more Python than I'd written in a while. I'm a PHP developer by trade and Python had been, until that point, a language I respected at a distance, like jazz. Building this thing meant living in it for a stretch. Type hints, async patterns, packaging, tests, the lot. Bonus prize: I came out of it more useful in a language I now actively reach for.

Once the basic tools worked the next ones were mostly copy-paste, and you start thinking, well, why not expose this endpoint as well, and that one, and oh hang on the API also lets you manage licences, custom fields, two-factor reset, LDAP sync, accessory check-outs, audit logs, the lot. Each new tool is a half-hour of work and a small dopamine hit when it returns the right shape of JSON. The hits add up. If you're ADHD and autistic, which I am, this is the part where the hyperfocus locks in and the rest of the evening simply ceases to exist. Before long I was 29 tools deep, writing README sections nobody would read, and at half ten on a Sunday night researching the precise semantic distinction between an accessory and a component in asset management software. Which is exactly the sort of distinction that nobody asks you about at parties.
The gap analysis
After tagging the first proper release I sat down with the full Snipe-IT API reference and walked it line by line, working out what I'd missed. Turns out: most of it. There are roughly 130 endpoints in the thing and I'd covered, generously, a third. Humbling, but useful. I now had a roadmap and a satisfying weekend backlog that wasn't laundry.
Versioned it. Tagged it. Emailed the Snipe-IT creators to let them know it existed, half-expecting the message to disappear into a void. It didn't. They wrote back, confirmed they'd take a look, and listed it. That level of grace from maintainers of a project that size isn't always the norm, and the courtesy was very much appreciated.
What happened next, which I was not expecting
Two things, in quick succession.
First, the upstream Snipe-IT project added the MCP server to the official list of community integrations. The commit that added it is here, if you fancy a small piece of internet evidence that I am not making this up.
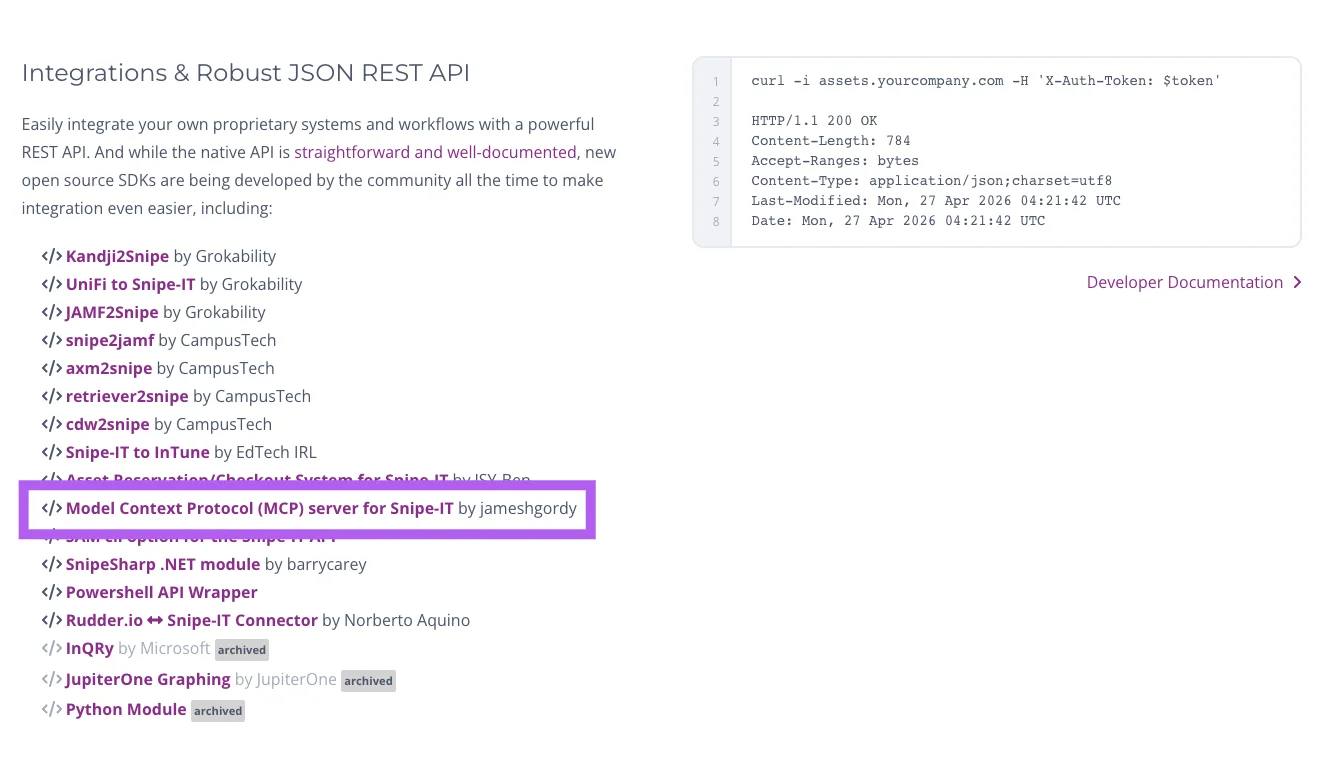
Second, and more meaningful to me, somebody I'd never met opened a pull request on the repo to fix a bug I hadn't yet noticed: the Snipe-IT API defaults to non-deterministic ordering on paginated requests, which means under certain conditions you'd get duplicate or missing records across pages. They diagnosed it, fixed it across all eleven list endpoints, wrote a clean commit message, and shipped it. For free. Because they used the thing and wanted it to work better.

This is the part of open source nobody tells you about. The recognition from the upstream project is a nice piece of paperwork. Strangers fixing your bugs because they care about the tool you wrote is something else entirely. It's the loop closing. It's the moment the project stops being mine and becomes ours.
The repo now sits in the double-digit star range. By the standards of modern internet attention this is nothing. By the standards of a thing I built on my own at half ten on a Sunday because the API was too modular for fluid AI interaction, it is more than enough.
The protocol is small. The patterns are simple. Build one.
If you use a piece of software every day and you've ever wished you could just talk to it, build the bridge. The protocol is open. The reference implementations are clear. The work is, in the most flattering possible sense, achievable.
You will write more code than you expected. You will spend a Sunday evening adjudicating the philosophical difference between two near-identical concepts in someone else's data model. You will, at some point, stare at an HTTP response and wonder if you've fundamentally misunderstood what an id field is. All of that is fine. It is, in fact, the job.
The reward is not just the tool. It's the realisation, halfway through, that you've stopped being a person who uses their tooling and become a person who shapes it. That's a different relationship with the software, and once you've had it, going back to clicking buttons feels a bit like being asked to wash up by hand when there's a dishwasher in the kitchen.
The Snipe-IT MCP server is on GitHub. It's MIT-licensed. Issues, pull requests, and unsolicited opinions are all welcome.